Qt Quick 场景图默认渲染器
本文档解释了默认场景图渲染器的内部工作原理,以便编写的代码能在性能和功能方面以最佳方式使用它。
要获得良好的性能,并不需要了解渲染器的内部结构。不过,在与场景图集成时,或在弄清为何无法最大限度地发挥图形芯片的效率时,这可能会有所帮助。
注: 即使在每一帧都是独一无二的,并且所有内容都是从头开始上传的情况下,默认渲染器也能表现出色。
QML 场景中的Qt Quick 项会填充QSGNode 实例树。一旦创建,这棵树就完整地描述了某一帧应如何渲染。它完全不包含对Qt Quick 项的任何引用,在大多数平台上,它都是在单独的线程中处理和渲染的。渲染器是场景图的一个自包含部分,它会遍历QSGNode 树,并使用QSGGeometryNode 中定义的几何体和QSGMaterial 中定义的着色器状态来更新图形状态和生成绘制调用。
如果需要,可以使用内部场景图后端 API 完全替换渲染器。这对于希望利用非标准硬件功能的平台供应商来说非常有趣。对于大多数用例,默认呈现器就足够了。
默认呈现器主要采用两种策略来优化呈现:批处理绘制调用和在 GPU 上保留几何图形。
批处理
传统的 2D 应用程序接口(如QPainter 、Cairo 或Context2D )是为处理每帧成千上万次单独的绘制调用而编写的,而 OpenGL 和其他硬件加速应用程序接口在绘制调用次数非常少且状态变化保持在最低水平时性能最佳。
注: 以下章节以OpenGL 为例,同样的概念也适用于其他图形 API。
请考虑以下用例:

绘制该列表的最简单方法是逐个单元格绘制。首先,绘制背景。这是一个特定颜色的矩形。在 OpenGL 术语中,这意味着选择一个着色器程序来进行纯色填充、设置填充颜色、设置包含 x 和 y 偏移量的变换矩阵,然后使用glDrawArrays 等工具绘制两个三角形来构成矩形。接下来绘制图标。在 OpenGL 术语中,这意味着选择一个着色器程序来绘制纹理、选择要使用的活动纹理、设置变换矩阵、启用阿尔法混合,然后使用glDrawArrays 等工具绘制两个三角形来构成图标的边界矩形。单元格之间的文本和分隔线也遵循类似的模式。列表中的每个单元格都要重复这一过程,因此对于较长的列表,OpenGL 状态更改和绘制调用带来的开销完全超过了使用硬件加速 API 所能带来的好处。
当每个基元都比较大时,这种开销可以忽略不计,但在典型的用户界面中,有许多小项目,这些小项目加起来的开销就相当可观了。
默认场景图渲染器会在这些限制条件下工作,并尝试将单个基元合并成批,同时保留完全相同的视觉效果。这样可以减少 OpenGL 状态变化和绘制调用,从而获得最佳性能。
不透明基元
渲染器将不透明基元和需要阿尔法混合的基元区分开来。通过使用 OpenGL 的 Z 缓冲区并赋予每个基元一个唯一的 Z 位置,渲染器可以自由地对不透明基元进行重新排序,而无需考虑它们在屏幕上的位置以及与之重叠的其他元素。通过查看每个基元的材质状态,渲染器将创建不透明批次。从Qt Quick 核心项目集来看,这包括具有不透明颜色的矩形项目和完全不透明的图像,如 JPEG 或 BMP。
使用不透明基元的另一个好处是,不透明基元不需要启用GL_BLEND ,这可能会造成相当高的成本,尤其是在移动和嵌入式 GPU 上。
在启用glDepthMask 和GL_DEPTH_TEST 的情况下,不透明基元以从前到后的方式进行渲染。在内部会进行早期 Z 检查的 GPU 上,这意味着片段着色器无需运行被遮挡的像素或像素块。需要注意的是,渲染器仍然需要考虑这些节点,顶点着色器仍然要为这些基元中的每个顶点运行,因此如果应用程序知道某些东西被完全遮挡,最好的办法是使用Item::visible 或Item::opacity 显式地隐藏它。
注: Item::z 用于控制一个项目相对于其同级项目的堆叠顺序。它与渲染器和 OpenGL 的 Z 缓冲没有直接关系。
Alpha 混合基元
绘制不透明基元后,渲染器将禁用glDepthMask ,启用GL_BLEND ,并以前后相接的方式渲染所有 Alpha 混合基元。
批量处理 Alpha 混合基元需要渲染器付出更多努力,因为重叠的元素需要以正确的顺序渲染,这样 Alpha 混合才会看起来正确。仅仅依靠 Z 缓冲区是不够的。渲染器会对所有进行 alpha 混合的基元进行遍历,除了查看它们的材质状态外,还会查看它们的边界矩形,以确定哪些元素可以分批渲染,哪些不可以。

在最左侧的情况下,蓝色背景可以在一次调用中绘制,而两个文本元素可以在另一次调用中绘制,因为文本只与堆叠在其前面的背景重叠。在最右边的情况中,"项目 4 "的背景与 "项目 3 "的文本重叠,因此在这种情况下,背景和文本需要分别使用不同的调用来绘制。
在 Z 方向上,alpha 基元与不透明节点交错,并可能在可用时触发 early-z,但同样,将Item::visible 设置为 false 总是更快。
与 3D 基元混合
场景图可以支持伪 3D 和正 3D 基元。例如,可以使用ShaderEffect 实现 "页面卷曲 "效果,或使用QSGGeometry 和自定义材质实现凹凸映射环。这样做时,需要考虑到默认渲染器已经使用了深度缓冲区。
渲染器会修改从 QSGMaterialShader::vertexShader() 返回的顶点着色器,并在应用模型视图和投影矩阵后压缩顶点的 z 值,然后在 z 值上添加一个小的平移,使其位于正确的 z 位置。
压缩假定 z 值的范围为 0 至 1。
纹理图集
活动纹理是唯一的 OpenGL 状态,这意味着使用不同 OpenGL 纹理的多个基元无法进行批处理。因此,Qt Quick 场景图允许将多个QSGTexture 实例分配为一个较大纹理的较小子区域,即纹理图集。
纹理图集的最大好处是,多个QSGTexture 实例现在可以引用同一个 OpenGL 纹理实例。这使得批量纹理绘制调用成为可能,例如图像项、BorderImage 项、ShaderEffect 项以及使用纹理的 C++ 类型(如QSGSimpleTextureNode 和自定义 QSGGeometryNodes)。
注意: 大型纹理不会进入纹理图集。
基于图集的纹理是通过向QQuickWindow::createTextureFromImage() 传递QQuickWindow::TextureCanUseAtlas 来创建的。
注: 基于 Atlas 的纹理没有从 0 到 1 的纹理坐标。请使用QSGTexture::normalizedTextureSubRect() 获取图集纹理坐标。
场景图会使用启发式方法计算图集的大小,以及输入图集的大小阈值。如果需要不同的值,可以使用环境变量QSG_ATLAS_WIDTH=[width] 、QSG_ATLAS_HEIGHT=[height] 和QSG_ATLAS_SIZE_LIMIT=[size] 来覆盖它们。对于平台供应商来说,更改这些值最有意义。
批量根节点
除了将兼容的基元合并到批次中外,默认渲染器还会尽量减少每帧需要发送到 GPU 的数据量。默认渲染器会识别属于一起的子树,并尝试将它们放入不同的批次中。一旦确定了批次,就会使用 "顶点缓冲对象"(Vertex Buffer Objects)将它们合并、上传并存储到 GPU 内存中。
转换节点
每个Qt Quick 项目都会在场景图树中插入一个QSGTransformNode ,以管理其 x、y、缩放或旋转。子项将在此变换节点下填充。默认渲染器会在帧与帧之间跟踪变换节点的状态,并查看子树以决定某个变换节点是否适合成为一组批次的根节点。在帧间发生变化且子树相当复杂的变换节点可以成为批次根节点。
批次根节点子树中的 QSGGeometryNodes 会在 CPU 上相对于根节点进行预变换。然后将它们上载并保留在 GPU 上。当变换发生变化时,渲染器只需更新根节点的矩阵,而无需更新每个单独的节点,因此列表和网格滚动速度非常快。在连续的帧中,只要节点没有被添加或删除,渲染列表实际上就是免费的。当有新内容进入子树时,获取新内容的批次会被重建,但速度仍然相对较快。在平移网格或列表时,每增加或移除一个节点,通常就会有几个不变的帧。
将变换节点识别为批次根的另一个好处是,它允许呈现器保留树中未发生变化的部分。例如,用户界面由列表和按钮行组成。当列表滚动、代表添加和删除时,用户界面的其余部分(即按钮行)保持不变,可以使用 GPU 上已存储的几何图形进行绘制。
转换节点成为批量根节点的节点和顶点阈值可以通过环境变量QSG_RENDERER_BATCH_NODE_THRESHOLD=[count] 和QSG_RENDERER_BATCH_VERTEX_THRESHOLD=[count] 来重写。重写这些标志对于平台供应商来说非常有用。
注: 在一个批次根节点下,会为每一组独特的材料状态和几何体类型创建一个批次。
剪切
将Item::clip 设置为 true 时,将在其几何体中创建一个带有矩形的QSGClipNode 。默认渲染器将通过 OpenGL 中的剪切来应用此剪辑。如果项目旋转的角度不是 90 度,则会使用 OpenGL 的模板缓冲区。 Qt Quick 通过 QML,Item 只支持将矩形设置为剪辑,但场景图 API 和默认渲染器可以使用任何形状进行剪辑。
在对子树应用剪辑时,需要使用唯一的 OpenGL 状态来渲染该子树。这意味着当Item::clip 为 true 时,对该项的批处理仅限于其子项。如果有很多子项(如ListView 或GridView ),或复杂的子项(如TextArea ),这样做没有问题。但是,在较小的项目上使用 clip 时应谨慎,因为它会阻止批处理。这包括按钮标签、文本字段或列表委托以及表格单元格。通常可以通过安排用户界面,使不透明项目覆盖 Flickable 周围的区域,或者依靠窗口边缘来剪辑其他内容,从而避免剪辑 Flickable(或项目视图)。
将Item::clip 设置为true 也会设置QQuickItem::ItemIsViewport 标志;带有QQuickItem::ItemObservesViewport 标志的子项可能会使用视口进行粗略的预剪辑步骤:例如Text 会省略完全位于视口之外的文本行。省略场景图节点或限制vertices 是一种优化,可以通过在 C++ 中设置flags 而不是在 QML 中设置Item::clip 来实现。
在自定义项目中实现QQuickItem::updatePaintNode() 时,如果能在较大的几何区域内渲染大量细节,就应该考虑将图形限制在视口内是否有效;如果有效,就可以设置ItemObservesViewport 标志,并从QQuickItem::clipRect() 中读取当前暴露的区域。这样做的一个结果是,updatePaintNode() 的调用次数会增加(通常每帧调用一次,只要内容在视口中移动即可)。
顶点缓冲区
每个批次都使用顶点缓冲对象(VBO)在 GPU 上存储数据。顶点缓冲在帧与帧之间保留,并在其所代表的场景图部分发生变化时进行更新。
默认情况下,渲染器会使用GL_STATIC_DRAW 将数据上传到 VBO。可以通过设置环境变量QSG_RENDERER_BUFFER_STRATEGY=[strategy] 来选择不同的上传策略。有效值为stream 和dynamic 。更改该值对平台供应商非常有用。
抗锯齿
场景图支持两种类型的抗锯齿。默认情况下,矩形和图像等基元将通过在基元边缘添加更多顶点来进行抗锯齿处理,从而使边缘逐渐变为透明。我们称这种方法为顶点抗锯齿。如果用户请求使用多采样 OpenGL 上下文,通过QQuickWindow::setFormat() 设置采样大于0 的QSurfaceFormat ,场景图将优先使用基于多采样的抗锯齿(MSAA)。这两种技术会影响内部渲染的方式,并有不同的限制。
也可以通过将环境变量QSG_ANTIALIASING_METHOD 设置为vertex 或msaa 来覆盖所使用的抗锯齿方法。
顶点抗锯齿会在相邻基元的边缘之间产生接缝,即使两个边缘在数学上是相同的。多采样抗锯齿则不会。
顶点抗锯齿
顶点抗锯齿可以使用Item::antialiasing 属性按项目启用或禁用。无论底层硬件支持何种抗锯齿功能,顶点抗锯齿都能正常工作,并为正常渲染的基元和捕捉到帧缓冲对象中的基元(例如使用ShaderEffectSource 类型)生成更高质量的抗锯齿效果。
使用顶点抗锯齿的缺点是,启用抗锯齿的每个基元都必须进行混合。就批处理而言,这意味着渲染器需要做更多的工作来确定基元是否可以批处理,而且由于与场景中的其他元素重叠,也可能导致批处理次数减少,从而影响性能。
在低端硬件上,混合的成本也会相当高,因此对于覆盖屏幕大部分区域的图像或圆角矩形来说,由于必须对整个基元进行混合,这些基元内部所需的混合量会导致显著的性能损失。
多采样抗锯齿
多采样抗锯齿是一种硬件功能,硬件会计算基元中每个像素的覆盖值。有些硬件能以极低的成本进行多采样,而其他硬件则可能需要更多内存和更多 GPU 周期来渲染帧。
使用多采样抗锯齿技术,许多基元(如圆角矩形和图像元素)都可以进行抗锯齿处理,而且在场景图中仍然是不透明的。这意味着渲染器在创建批次时可以更轻松地工作,并可依靠早期 Z 来避免过度绘制。
使用多采样抗锯齿时,渲染到帧缓冲对象中的内容需要额外的扩展来支持帧缓冲的多采样。通常是GL_EXT_framebuffer_multisample 和GL_EXT_framebuffer_blit 。大多数台式机芯片都有这些扩展,但在嵌入式芯片中并不常见。当硬件中不提供帧缓冲器多采样功能时,渲染到帧缓冲器对象中的内容将无法进行抗锯齿处理,包括ShaderEffectSource 中的内容。
性能
正如开头所述,要获得良好的性能,并不需要了解渲染器的更多细节。渲染器的编写目的是针对常见使用情况进行优化,几乎在任何情况下都能表现出色。
- 良好的性能来自有效的批处理,尽可能减少几何体的重复上传。通过设置环境变量
QSG_RENDERER_DEBUG=render,渲染器会输出有关批处理进行情况、使用了多少批处理、保留了哪些批处理、哪些批处理不透明或不透明的统计数据。为了达到最佳性能,只有在真正需要时才上传,批次应少于 10 个,其中至少有 3-4 个批次是不透明的。 - 默认渲染器不会在 CPU 端进行视口剪切或遮挡检测。如果某些东西不应该可见,就不应该显示。对于不应绘制的项目,请使用
Item::visible: false。不添加此类逻辑的主要原因是它会增加额外的成本,这也会损害那些小心谨慎的应用程序。 - 确保使用纹理图集。图像和BorderImage 项将使用该图集,除非图像太大。对于用 C++ 创建的纹理,请在调用 QQuickWindow::createTexture() 时通过QQuickWindow::TextureCanUseAtlas 。通过设置环境变量
QSG_ATLAS_OVERLAY,所有图集纹理都将着色,以便在应用程序中易于识别。 - 尽可能使用不透明基元。不透明基元在渲染器中的处理速度更快,在 GPU 上的绘制速度也更快。例如,PNG 文件通常会有一个 alpha 通道,尽管每个像素都是完全不透明的。而 JPG 文件总是不透明的。在向QQuickImageProvider 提供图像或使用QQuickWindow::createTextureFromImage() 创建图像时,尽可能让图像具有QImage::Format_RGB32 。
- 请注意,重叠的复合项目(如上图所示)不能批处理。
- 剪切会破坏批处理。切勿在表格单元格、项目委托或类似内容中按项目使用。使用分隔代替剪切文本。与其剪切图像,不如创建一个QQuickImageProvider ,返回剪切后的图像。
- 批处理仅适用于 16 位索引。所有内置项都使用 16 位索引,但自定义几何体也可自由使用 32 位索引。
- 某些材质标志会阻止批处理,其中限制最大的是QSGMaterial::RequiresFullMatrix ,它会阻止所有批处理。
- 使用单色背景的应用程序应使用QQuickWindow::setColor() 进行设置,而不是使用顶层的矩形项。QQuickWindow::setColor() 将在调用
glClear()时使用,这样可能会更快。 - Mipmapped 图像项目不会放在全局图集中,也不会被批处理。
- OpenGL 驱动程序中一个与帧缓冲对象 (FBO) 回读有关的错误可能会损坏已渲染的字形。如果设置了
QML_USE_GLYPHCACHE_WORKAROUND环境变量,Qt XML 会在 RAM 中保留字形的额外副本。这意味着在绘制之前未绘制过的字形时,性能会略有降低,因为 Qt 要通过 CPU 访问额外的副本。这也意味着字形缓存将占用两倍的内存。但质量不会受此影响。
如果应用程序性能不佳,请确保渲染实际上是瓶颈所在。使用剖析器!环境变量QSG_RENDER_TIMING=1 会输出大量有用的时序参数,有助于找出问题所在。
可视化
要可视化场景图默认渲染器的各个方面,可将QSG_VISUALIZE 环境变量设置为以下各节中详细说明的值之一。我们使用以下 QML 代码提供了一些变量输出的示例:
import QtQuick 2.2 Rectangle { width: 200 height: 140 ListView { id: clippedList x: 20 y: 20 width: 70 height: 100 clip: true model: ["Item A", "Item B", "Item C", "Item D"] delegate: Rectangle { color: "lightblue" width: parent.width height: 25 Text { text: modelData anchors.fill: parent horizontalAlignment: Text.AlignHCenter verticalAlignment: Text.AlignVCenter } } } ListView { id: clippedDelegateList x: clippedList.x + clippedList.width + 20 y: 20 width: 70 height: 100 clip: true model: ["Item A", "Item B", "Item C", "Item D"] delegate: Rectangle { color: "lightblue" width: parent.width height: 25 clip: true Text { text: modelData anchors.fill: parent horizontalAlignment: Text.AlignHCenter verticalAlignment: Text.AlignVCenter } } } }
对于左边的ListView ,我们将其clip 属性设置为true 。对于右侧的ListView ,我们还将每个委托的clip 属性设置为true ,以说明剪切对批处理的影响。

原文
注: 可视化元素不尊重剪切,渲染顺序也是任意的。
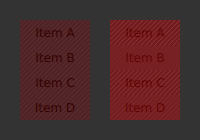
批次可视化
将QSG_VISUALIZE 设置为batches 可在呈现器中可视化批次。合并的批次用纯色绘制,未合并的批次用对角线图案绘制。独特颜色越少,说明批次越好。如果未合并的批次包含许多单独的节点,则表示批次不佳。

QSG_VISUALIZE=batches
可视化剪切
将QSG_VISUALIZE 设置为clip 会在场景顶部绘制红色区域,表示剪切。由于Qt Quick 项目默认不会剪切,因此通常不会显示剪切。
QSG_VISUALIZE=clip
可视化变化
将QSG_VISUALIZE 设置为changes 可视化渲染器中的变化。场景图中的变化通过随机颜色的闪烁叠加可视化。基元上的变化用纯色可视化,而祖先的变化(如矩阵或不透明度变化)用图案可视化。
可视化叠加绘制
将QSG_VISUALIZE 设置为overdraw 可将渲染器中的过度绘制可视化。可视化 3D 中的所有项目,以突出显示过度绘制。该模式还可用于在一定程度上检测视口以外的几何体。不透明的项目将以绿色色调呈现,而半透明的项目将以红色色调呈现。视口的边界框用蓝色呈现。不透明的内容更容易被场景图处理,通常渲染速度也更快。
请注意,上面代码中的根矩形是多余的,因为窗口也是白色的,所以在这种情况下绘制矩形是在浪费资源。将其更改为 Item 可以略微提高性能。


QSG_VISUALIZE=overdraw
通过 Qt 渲染硬件接口进行渲染
从 Qt 6.0 开始,默认适配总是通过图形抽象层(Qt Rendering Hardware Interface,RHI)进行渲染。 Qt GUI模块提供的图形抽象层,即 Qt 渲染硬件接口(RHI)。这意味着,与 Qt 5 不同,场景图形不会直接调用 OpenGL。相反,它通过使用 RHI API 来记录资源和绘制命令,然后将命令流转化为 OpenGL、Vulkan、Metal 或 Direct 3D 调用。着色器处理也是统一的,只需编写一次着色器代码,编译到SPIR-V,然后翻译成适合各种图形 API 的语言即可。
要控制行为,可以使用以下环境变量:
| 环境变量 | 可能值 | 描述 |
|---|---|---|
QSG_RHI_BACKEND | vulkan,metal,opengl,d3d11 、d3d12 | 请求特定的 RHI 后端。默认情况下,根据平台选择目标图形 API,除非该变量或等效的 C++ API 改写了该 API。默认情况下,Windows 使用 Direct3D 11,macOS 使用 Metal,其他平台使用 OpenGL。 |
QSG_INFO | 1 | 与基于 OpenGL 的渲染路径一样,在初始化Qt Quick 场景图时,设置此项可以打印系统信息。这对故障排除非常有用。 |
QSG_RHI_DEBUG_LAYER | 1 | 在适用的情况下(Vulkan、Direct3D),启用图形 API 实现的调试层或验证层(如果可用),可以是图形设备上的,也可以是实例对象上的。对于 macOS 上的 Metal,请设置环境变量METAL_DEVICE_WRAPPER_TYPE=1 。 |
QSG_RHI_PREFER_SOFTWARE_RENDERER | 1 | 请求选择使用基于软件的光栅化的适配器或物理设备。仅在底层 API 支持枚举适配器(例如 Direct3D 或 Vulkan)时适用,否则将忽略。 |
希望始终使用单个给定图形 API 运行的应用程序也可以通过 C++ 提出请求。例如,在构建任何QQuickWindow 之前,在 main() 中的早期调用会强制使用 Vulkan(否则会失败):
QQuickWindow::setGraphicsApi(QSGRendererInterface::Vulkan);
请参见QSGRendererInterface::GraphicsApi 。枚举值OpenGL,Vulkan,Metal,Direct3D11,Direct3D12 的效果等同于将QSG_RHI_BACKEND 设置为等效的字符串键。
除非被QSG_RHI_PREFER_SOFTWARE_RENDERER 或特定于后端变量(如QT_D3D_ADAPTER_INDEX 或QT_VK_PHYSICAL_DEVICE_INDEX )覆盖,否则所有QRhi 后端都将选择系统默认的 GPU 适配器或物理设备。目前不提供进一步的适配器配置功能。
从 Qt 6.5 开始,以前只能作为环境变量公开的一些设置可作为QQuickGraphicsConfiguration 中的 C++ API 使用。例如,设置QSG_RHI_DEBUG_LAYER 和调用setDebugLayer(true) 是等价的。
© 2026 The Qt Company Ltd. Documentation contributions included herein are the copyrights of their respective owners. The documentation provided herein is licensed under the terms of the GNU Free Documentation License version 1.3 as published by the Free Software Foundation. Qt and respective logos are trademarks of The Qt Company Ltd. in Finland and/or other countries worldwide. All other trademarks are property of their respective owners.
