Performance Analyzer
Analyze the CPU and memory usage of an application on Linux desktop and embedded devices.
To set global preferences for Performance Analyzer, go to Preferences > Analyzer > CPU Usage.
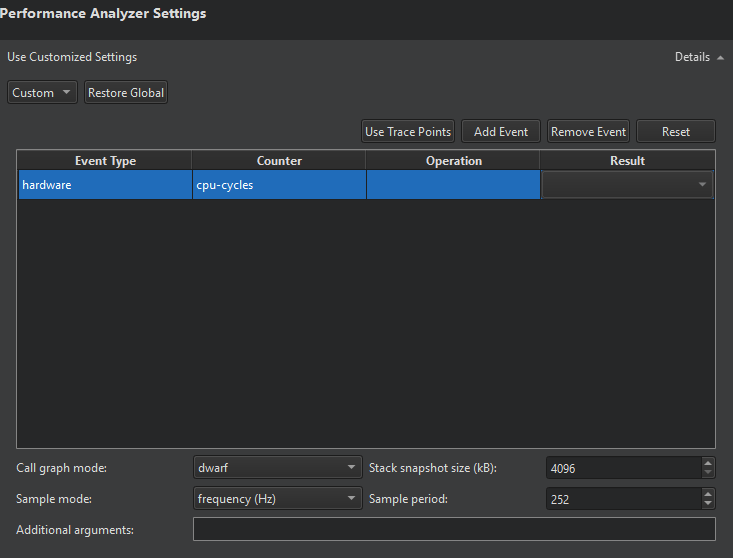
To set preferences for a particular run configuration, go to Projects > Run Settings and select Details next to Performance Analyzer Settings.
To edit the settings for the current run configuration, select the drop down menu next to  on the Performance Analyzer toolbar.
on the Performance Analyzer toolbar.

Choosing event types
The events table lists the events that trigger Performance Analyzer to take a sample. The most common way of analyzing CPU usage involves periodic sampling, driven by hardware performance counters that react to the number of instructions or CPU cycles executed. You can also select a software counter that uses the CPU clock.
Select Add Event to add events to the table. In Event Type, select the general type of event to be sampled, most commonly hardware or software. In Counter, select the counter for the sampling. For example, instructions in the hardware group or cpu-clock in the software group.
More specialized sampling, for example by cache misses or cache hits, is possible. However, support for it depends on specific features of the CPU. For those specialized events, give more detailed sampling instructions in Operation and Result. For example, select a cache event for L1-dcache on the load operation with a result of misses to sample L1-dcache misses on reading.
Select Remove Event to remove the selected event from the table.
Select Use Trace Points to replace the current selection of events with trace points defined on the target device and set the Sample mode to event count and the Sample period to 1. If Create Trace Points defines the trace points on the target, Performance Analyzer automatically uses them to profile memory usage.
Select Reset to revert the selection of events, as well as Sample mode and Sample period to the default values.
Choosing a sampling mode and period
In Sample mode and Sample period, specify how samples are triggered:
- Sampling by event count instructs the kernel to take a sample every
ntimes one of the chosen events has occurred, wherenis set in Sample period. - Sampling by frequency (Hz) instructs the kernel to try and take a sample
ntimes per second, by automatically adjusting the sampling period. Setnin Sample period.
High frequencies or low event counts result in more accurate data, at the expense of a higher overhead and a larger volume of data being generated. The actual sampling period is determined by the Linux kernel on the target device, which takes the period set for Perf merely as advice. There may be a significant difference between the sampling period you request and the actual result.
In general, if you configure Performance Analyzer to collect more data than it can transmit over the connection between the target and the host device, the application may get blocked while Perf is trying to send the data, and the processing delay may grow excessively. You should then change the value of Sample period or Stack snapshot size.
Selecting call graph mode
In Call graph mode, you can specify how Performance Analyzer recovers call chains from your application:
- The Frame Pointer, or
fp, mode relies on frame pointers being available in the profiled application and will instruct the kernel on the target device to walk the chain of frame pointers in order to retrieve a call chain for each sample. - The Dwarf mode works also without frame pointers, but generates significantly more data. It takes a snapshot of the current application stack each time a sample is triggered and transmits that snapshot to the host computer for analysis.
- The Last Branch Record mode does not use a memory buffer. It automatically decodes the last 16 taken branches every time execution stops. It is supported only on recent Intel CPUs.
Qt and most system libraries are compiled without frame pointers by default, so the frame pointer mode is only useful with customized systems.
Setting stack snapshot size
Performance Analyzer analyzes and unwinds the stack snapshots generated by Perf in dwarf mode. Set the size of the stack snapshots in Stack snapshot size. Large stack snapshots result in a larger volume of data to be transferred and processed. Small stack snapshots may fail to capture call chains of highly recursive applications or other intense stack usage.
Adding command-line options for Perf
Set additional command-line options to pass to Perf when recording data in Additional arguments. Set --no-delay or --no-buffering to reduce the processing delay. However, those options are not supported by all versions of Perf and Perf may not start if an unsupported option is given.
Resolving names for JIT-compiled JavaScript functions
Since version 5.6.0, Qt can generate perf.map files with information about JavaScript functions. Performance Analyzer will read them and show the function names in the Timeline, Statistics, and Flame Graph views. This only works if the process being profiled is running on the host computer, not on the target device. To switch on the generation of perf.map files, add the environment variable QV4_PROFILE_WRITE_PERF_MAP to Run Environment and set its value to 1.
Analyzing collected data
The Timeline view displays a graphical representation of CPU usage per thread and a condensed view of all recorded events.
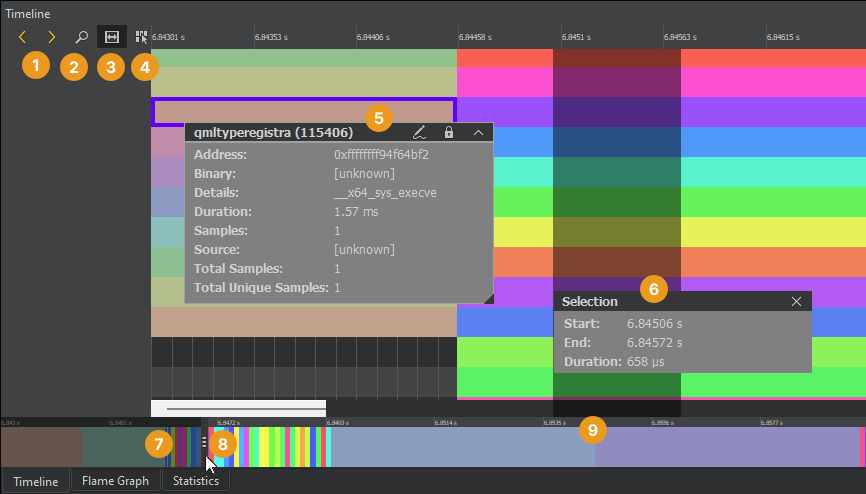
Each category in the timeline describes a thread in the application. Move the cursor on an event (5) on a row to see how long it takes and which function in the source it represents. To display the information only when an event is selected, turn off View Event Information on Mouseover (4).
The outline (9) summarizes the period for which data was collected. Drag the zoom range (7) or select the outline to move on the outline. You can also move between events by selecting Jump to Previous Event and Jump to Next Event (1).
Select Show Zoom Slider button (2) to open a slider that sets the zoom level. You can also drag the zoom handles (8). To reset the default zoom level, right-click the timeline to open the context menu, and select Reset Zoom.
Selecting event ranges
Select an event range (6) to view the time it represents or to zoom into a specific region of the trace. Select Select Range (3) to activate the selection tool. Then click in the timeline to specify the beginning of the event range. Drag the selection handle to define the end of the range.
Use event ranges also to measure delays between two subsequent events. Place a range between the end of the first event and the beginning of the second event. Duration shows the delay between the events in milliseconds.
To zoom into an event range, double-click it.
To remove an event range, close the Selection dialog.
Understanding the data
Generally, events in the timeline view indicate how long a function call took. Move the mouse over them to see details. The details always include the address of the function, the approximate duration of the call, the ELF file the function resides in, the number of samples collected with this function call active, the total number of times this function was encountered in the thread, and the number of samples this function was encountered in at least once.
For functions with debug information available, the details include the location in source code and the name of the function. You can select such events to move the cursor in the code editor to the part of the code the event is associated with.
As the Perf tool only collects periodic samples, Performance Analyzer cannot determine the exact time when a function was called or when it returned. You can, however, see exactly when a sample was taken in the second row of each thread. Performance Analyzer assumes that if the same function is present at the same place in the call chain in multiple consecutive samples, then this represents a single call to the respective function. This is, of course, a simplification. Also, there may be other functions being called between the samples taken, which do not show up in the profile data. However, statistically, the data is likely to show the functions that spend the most CPU time most prominently.
If a function without debug information is encountered, further unwinding of the stack may fail. Unwinding will also fail for some symbols implemented in assembly language. If unwinding fails, only a part of the call chain is displayed, and the surrounding functions may seem to be interrupted. This does not necessarily mean they were actually interrupted during the execution of the application, but only that they could not be found in the stacks where the unwinding failed.
JavaScript functions from the QML engine running in the JIT mode can be unwound. However, their names will only be displayed when QV4_PROFILE_WRITE_PERF_MAP is set. Compiled JavaScript generated by the Qt Quick Compiler can also be unwound. In this case the C++ names generated by the compiler are shown for JavaScript functions, rather than their JavaScript names. When running in interpreted mode, stack frames involving QML can also be unwound, showing the interpreter itself, rather than the interpreted JavaScript.
Kernel functions included in call chains are shown on the third row of each thread.
The coloring of the events represents the actual sample rate for the specific thread they belong to, across their duration. The Linux kernel will only take a sample of a thread if the thread is active. At the same time, the kernel tries to honor the requested event period. Thus, differences in the sampling frequency between different threads indicate that the thread with more samples taken is more likely to be the overall bottleneck, and the thread with less samples taken has likely spent time waiting for external events such as I/O or a mutex.
Viewing statistics
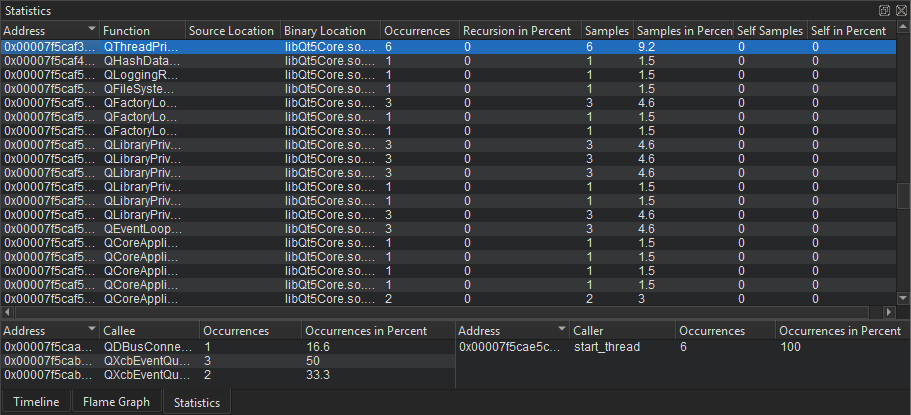
The Statistics view displays the number of samples each function in the timeline was contained in, in total and when on the top of the stack (called self). This allows you to examine which functions you need to optimize. A high number of occurrences might indicate that a function is triggered unnecessarily or takes very long to execute.
Select a row to move to the respective function in the source code in the code editor.
The Callers and Callees panes show dependencies between functions. They allow you to examine the internal functions of the application. The Callers pane summarizes the functions that called the function selected in the main view. The Callees pane summarizes the functions called from the function selected in the main view.
Select a row to move to the respective function in the source code in the code editor and select it in the main view.
To copy the contents of one view or row to the clipboard, select Copy Table or Copy Row in the context menu.
Visualizing statistics as flame graphs
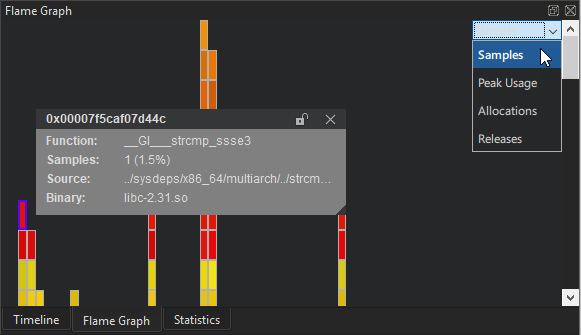
The Flame Graph view shows a more concise statistical overview of the execution. The horizontal bars show an aspect of the samples taken for a certain function, relative to the same aspect of all samples together. The nesting shows which functions were called by which other ones.
The Visualize button lets you select what aspect to show in the Flame Graph.
- Samples is the default visualization. The size of the horizontal bars represents the number of samples recorded for the given function.
- In Peak Usage mode, the size of the horizontal bars represents the amount of memory allocated by the respective functions, at the point in time when the allocation's memory usage was at its peak.
- In Allocations mode, the size of the horizontal bars represents the number of memory allocations triggered by the respective functions.
- In Releases mode, the size of the horizontal bars represents the number of memory releases triggered by the respective functions.
The Peak Usage, Allocations, and Releases modes will only show any data if samples from memory trace points have been recorded.
Interaction between the views
When you select a stack frame in either of the Timeline, Flame Graph, or Statistics views, information about it is displayed in the other two views. To view a time range in the Statistics and Flame Graph views, select Analyze > Performance Analyzer Options > Limit to the Range Selected in Timeline. To show the full stack frame, select Show Full Range.
Loading perf data files
You can load any perf.data files generated by recent versions of the Linux Perf tool and view them in Qt Creator. Select Analyze > Performance Analyzer Options > Load perf.data File to load a file.
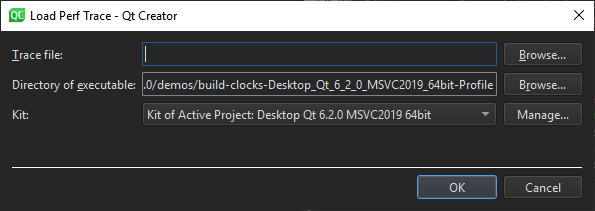
Performance Analyzer needs to know the context in which the data was recorded to find the debug symbols. Therefore, you have to specify the kit that the application was built with and the folder where the application executable is located.
The Perf data files are generated by calling perf record. Make sure to generate call graphs when recording data by starting Perf with the --call-graph option. Also check that the necessary debug symbols are available to Performance Analyzer, either at a standard location (/usr/lib/debug or next to the binaries), or as part of the Qt package you are using.
Performance Analyzer can read Perf data files generated in either frame pointer or dwarf mode. However, to generate the files correctly, numerous preconditions have to be met. All system images for the supported embedded platforms are correctly set up for profiling in the dwarf mode. For other devices, check whether Perf can read back its own data in a sensible way by checking the output of perf report or perf script for the recorded Perf data files.
Loading and saving trace files
You can save and load trace data in a format specific to the Performance Analyzer (.ptq). This format is self-contained, and therefore loading it does not require you to specify the recording environment. You can transfer such trace files to a different computer without any toolchain or debug symbols and analyze them there.
To load trace data, go to Analyze > Performance Analyzer Options > Load Trace File.
To save trace data, select Save Trace File.
Troubleshooting
Performance Analyzer might fail to record data for the following reasons:
- Perf events may be globally disabled on your system. The preconfigured Boot to Qt images come with Perf events enabled. For a custom configuration you need to make sure that the file
/proc/sys/kernel/perf_event_paranoidcontains a value smaller than2. For maximum flexibility in recording traces you can set the value to-1. This allows any user to record any kind of trace, even using raw kernel trace points.The way to enable Perf events depends on your Linux distribution. On some distributions, you can run the following command with root (or equivalent) privileges:
echo -e "kernel.perf_event_paranoid=-1\nkernel.kptr_restrict=0" | sudo tee /etc/sysctl.d/10-perf.conf
- The connection between the target device and the host may not be fast enough to transfer the data produced by Perf. Try modifying the values of the Stack snapshot size or Sample period settings.
- Perf may be buffering the data forever, never sending it. Add
--no-delayor--no-bufferingto Additional arguments. - Some versions of Perf will not start recording unless given a certain minimum sampling frequency. Try setting Sample period to 1000.
- On some devices, in particular various i.MX6 Boards, the hardware performance counters are dysfunctional and the Linux kernel may randomly fail to record data after some time. Perf can use different types of events to trigger samples. You can get a list of available event types by running
perf liston the device and then select the respective event types in the settings. The choice of event type affects the performance and stability of the sampling. Thecpu-clocksoftwareevent is a safe but relatively slow option as it does not use the hardware performance counters, but drives the sampling from software. After the sampling has failed, reboot the device. The kernel may have disabled important parts of the performance counters system. - Perf might not be installed. The way to install it depends on your Linux distribution. For example, try the following commands:
- On Ubuntu 22.04:
sudo apt install linux-tools-$(uname -r) - On Debian:
apt install linux-perf
- On Ubuntu 22.04:
The General Messages view shows output from the helper program that processes the data.
The Application Output view shows some information even if the Performance Analyzer displays error messages.
See also How to: Analyze, Analyzers, Analyzing code, and Managing kits.
Copyright © The Qt Company Ltd. and other contributors. Documentation contributions included herein are the copyrights of their respective owners. The documentation provided herein is licensed under the terms of the GNU Free Documentation License version 1.3 as published by the Free Software Foundation. Qt and respective logos are trademarks of The Qt Company Ltd in Finland and/or other countries worldwide. All other trademarks are property of their respective owners.
