コンテナクラス
はじめに
Qt ライブラリでは、テンプレート・ベースの汎用コンテナ・クラスを提供しています。これらのクラスは、指定された型のアイテムを格納するために使用することができます。例えば、QStringのサイズ変更可能な配列が必要な場合、QList<QString> を使用します。
これらのコンテナ・クラスは、STLコンテナよりも軽く、安全で、使いやすいように設計されています。STLに慣れていない場合や、"Qt流 "に物事を進めたい場合は、STLクラスの代わりにこれらのクラスを使うことができます。
コンテナ・クラスは暗黙的に共有され、リエントラント(再入可能)であり、速度、メモリ消費量、最小限のインライン・コード拡張のために最適化されているため、実行可能ファイルのサイズが小さくなります。さらに、これらのコンテナ・クラスは、それらにアクセスするために使用されるすべてのスレッドによって読み取り専用コンテナとして使用される状況では、スレッドセーフです。
コンテナはトラバーサル用のイテレータを提供する。STL 形式のイテレータは最も効率的なもので、Qt や STL のgeneric algorithms とともに使用できます。Javaスタイルのイテレータは、後方互換性のために提供されています。
注意: Qt 5.14 以降、ほとんどのコンテナクラスで範囲コンストラクタが利用できるようになりました。QMultiMap は特筆すべき例外です。Qt 5 の様々な非推奨の from/to メソッドを置き換えるために、これらの使用を推奨します。例えば
QList<int> list = {1, 2, 3, 4, 4, 5}; QSet<int> set(list.cbegin(), list.cend()); /* Will generate a QSet containing 1, 2, 3, 4, 5. */
コンテナクラス
Qt は以下の連続したコンテナを提供します:QList QStack およびQQueue です。ほとんどのアプリケーションでは、QList を使用するのが最適です。非常に高速な追加を行うことができます。本当にリンクリストが必要な場合は、std::listを使用してください。QStack とQQueue は、LIFOとFIFOのセマンティクスを提供する便利なクラスです。
Qtはこれらの連想コンテナも提供しています:QMap QMultiMap 、QHash 、QMultiHash 、QSet 。Multi "コンテナは、1つのキーに関連付けられた複数の値を便利にサポートします。Hash "コンテナは、ソートされた集合のバイナリ検索の代わりにハッシュ関数を使用することで、より高速な検索を提供します。
特別なケースとして、QCache とQContiguousCache クラスは、限られたキャッシュ・ストレージ内のオブジェクトの効率的なハッシュ・ルックアップを提供します。
| クラス | 概要 |
|---|---|
| QList<T> | これは、圧倒的によく使われるコンテナ・クラスです。インデックスによってアクセスできる、与えられた型(T)の値のリストを格納します。内部的には、与えられた型の値の配列をメモリ上の隣接した位置に格納します。リストの先頭や真ん中に挿入すると、メモリ上の位置を1つずつ移動しなければならないアイテムが大量に発生するため、かなり時間がかかることがあります。 |
| QVarLengthArray<T, Prealloc> | これは低レベルの可変長配列を提供する。速度が特に重要な場所では、QList の代わりに使うことができます。 |
| QStack<T> | これはQList の便利なサブクラスで、"last in, first out" (LIFO) セマンティクスを提供する。QList push()、pop()、top() がある。 |
| QQueue<T> | これはQList の便利なサブクラスで、"先入れ先出し"(FIFO)セマンティクスを提供する。QList 、enqueue()、dequeue()、head()。 |
| QSet<T> | これは、高速ルックアップが可能な単一値の数学集合を提供する。 |
| QMap<Key, T> | これは、Key型のキーをT型の値にマップする辞書(連想配列)を提供する。通常、各キーは1つの値に関連付けられています。QMap そのデータはキーの順番で格納されます。順番が重要でない場合は、QHash がより高速な代替手段です。 |
| QMultiMap<Key, T> | 等価な複数のキーを挿入できることを除けば、QMap のような辞書を提供する。 |
| QHash<Key, T> | これは、QMap とほぼ同じAPIを持つが、かなり高速な検索を提供する。QHash は、任意の順序でデータを格納する。 |
| QMultiHash<Key, T> | これは、複数の等価なキーを挿入できる点を除き、QHash と同様に、ハッシュ表ベースの辞書を提供する。 |
コンテナは入れ子にすることができる。たとえば、QMap<QString,QList<int>のように、キーの型がQString 、値の型がQList<int>のようにすることは完全に可能である。
コンテナは、コンテナと同じ名前の個々のヘッダーファイルで定義される(例:<QList> )。便宜上、コンテナは<QtContainerFwd> で前方宣言される。
さまざまなコンテナに格納される値は、割り当て可能なデータ型であれば何でもよい。修飾するためには、型はコピーコンストラクタと代入演算子を提供しなければならない。操作によっては、デフォルト・コンストラクタも必要です。これは、int やdouble のような基本型、ポインタ型、QString 、QDate 、QTime のような Qt データ型など、コンテナに格納したいと思うほとんどのデータ型をカバーしますが、QObject やQObject のサブクラス(QWidget 、QDialog 、QTimer など)はカバーしません。QList<QWidget> をインスタンス化しようとすると、コンパイラはQWidget のコピー・コンストラクタと代入演算子が無効になっていると文句を言います。この種のオブジェクトをコンテナに格納する場合は、QList<QWidget *> のように、ポインタとして格納します。
以下に、割り当て可能なデータ型の要件を満たすカスタム・データ型の例を示します:
class Employee { public: Employee() {} Employee(const Employee &other); Employee &operator=(const Employee &other); private: QString myName; QDate myDateOfBirth; };
コピー・コンストラクタや代入演算子を提供しない場合、C++はメンバごとのコピーを実行するデフォルトの実装を提供します。上の例では、これで十分でした。また、コンストラクタを提供しない場合、C++はデフォルト・コンストラクタを使用してメンバを初期化するデフォルト・コンストラクタを提供します。明示的なコンストラクタや代入演算子は提供されていませんが、以下のようなデータ型をコンテナに格納することができます:
コンテナによっては、格納できるデータ型に追加の要件があります。例えば、QMap<Key, T>のKey型は、operator<() を提供しなければならない。このような特別な要件は、クラスの詳細説明に記述されています。場合によっては、特定の関数に特別な要求があることもあります。要件が満たされない場合、コンパイラは常にエラーを出します。
Qt のコンテナは operator<<() と operator>>() を提供し、QDataStream を使って簡単に読み書きできるようになっています。 つまり、コンテナに格納されるデータ型も operator<<() と operator>>() をサポートしていなければなりません。このようなサポートを提供するのは簡単です。ここでは、上記のMovie構造体についてその方法を説明します:
QDataStream &operator<<(QDataStream &out, const Movie &movie) { out << (quint32)movie.id << movie.title << movie.releaseDate; return out; } QDataStream &operator>>(QDataStream &in, Movie &movie) { quint32 id; QDate date; in >> id >> movie.title >> date; movie.id = (int)id; movie.releaseDate = date; return in; }
たとえば、QList は自動的にデフォルトで構成された値で項目を初期化し、QMap::value() は指定されたキーがマップにない場合にデフォルトで構成された値を返します。ほとんどの値型では、これは単にデフォルトのコンストラクタを使用して値が作成されることを意味します(QString の場合は空文字列など)。しかし、int やdouble のようなプリミティブ型やポインタ型の場合、C++ 言語は初期化を指定していません。これらの場合、Qt のコンテナは自動的に値を 0 に初期化します。
コンテナの繰り返し処理
範囲ベースの
コンテナには、範囲ベースfor を使うのが望ましい:
非 const コンテキストで Qt コンテナを使用する場合、暗黙的な共有はコンテナの望ましくないデタッチを実行する可能性があることに注意してください。これを防ぐには、std::as_const() を使用してください:
連想コンテナの場合、これは値をループします。
インデックス・ベース
アイテムがメモリ内で連続的に格納されるシーケンシャル・コンテナ(たとえば、QList )では、インデックス・ベースのイテレーションを使用できます:
QList<QString> list = {"A", "B", "C", "D"}; for (qsizetype i = 0; i < list.size(); ++i) { const auto &item = list.at(i); //... }
イテレータ・クラス
イテレータは、コンテナ内のアイテムにアクセスするための統一された手段を提供します。Qtのコンテナ・クラスは、2種類のイテレータを提供します:STLスタイルのイテレータとJavaスタイルのイテレータです。どちらのタイプのイテレータも、コンテナ内のデータが変更されたり、constでないメンバ関数の呼び出しによって暗黙の共有コピーから切り離されたりすると、無効になります。
STLスタイルのイテレータ
STLスタイルのイテレータはQt 2.0のリリースから利用可能です。これらは Qt と STL のgeneric algorithms と互換性があり、速度のために最適化されています。
各コンテナ・クラスには、2 つの STL スタイルのイテレータがあります:1 つは読み取り専用、もう 1 つは読み取り/書き込み専用です。読み取り専用イテレータは、読み取り/書き込みイテレータよりも高速であるため、可能な限り使用する必要があります。
| コンテナ | 読み取り専用イテレータ | 読み書きイテレータ |
|---|---|---|
| QList<t>,QStack<t>,QQueue<t> | QList<T>::const_iterator | QList<T>::iterator |
| QSet<T> | QSet<T>::const_iterator | QSet<T>::iterator |
| QMap<Key, T>,QMultiMap<Key, T>::const_iterator | QMap<Key, T>::const_iterator | QMap<Key, T>::iterator |
| QHash<Key, T>,QMultiHash<Key, T>::const_iterator | QHash<Key, T>::const_iterator | QHash<Key, T>::iterator |
STLイテレータのAPIは、配列のポインタをモデルにしている。例えば、++ 演算子はイテレータを次のアイテムに進め、* 演算子はイテレータが指すアイテムを返します。実際、QList とQStack では、アイテムを隣接するメモリ位置に格納するため、iterator 型はT * の typedef にすぎず、const_iterator 型はconst T * の typedef にすぎません。
この議論では、QList とQMap に集中する。QSet QList同様に、QHash のイテレータ型はQMap のイテレータ型と同じインタフェースを持つ。
以下は、QList<QString> のすべての要素を順番に繰り返し、小文字に変換する典型的なループです:
QList<QString> list = {"A", "B", "C", "D"}; for (auto i = list.begin(), end = list.end(); i != end; ++i) *i = (*i).toLower();
STLスタイルのイテレータは、項目を直接指定します。コンテナのbegin() 関数は、コンテナ内の最初の項目を指すイテレータを返します。コンテナのend() 関数は、コンテナ内の最後のアイテムの 1 つ前の位置を指すイテレータを返します。end() は無効な位置を示すので、決して再参照してはならない。これは通常、ループのブレーク条件で使われる。リストが空の場合、begin() はend() と等しいので、ループは実行されない。
下の図は、4つの項目を含むリストについて、イテレータの有効な位置を赤い矢印で示しています:
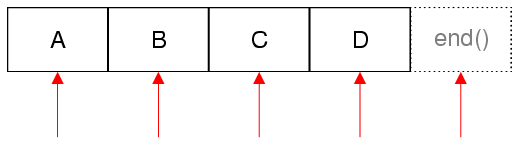
STLスタイルのイテレータで逆方向の反復処理を行うには、逆イテレータを使用します:
QList<QString> list = {"A", "B", "C", "D"}; for (auto i = list.rbegin(), rend = list.rend(); i != rend; ++i) *i = i->toLower();
ここまでのコード・スニペットでは、単項演算子* を使って、あるイテレータ位置に格納されているアイテム(型はQString )を取り出し、それに対してQString::toLower ()を呼び出した。
読み取り専用アクセスには、const_iterator、cbegin ()、cend ()を使用できます。例えば
for(autoi=list.cbegin(),end=list.cend(); i!=end;++i) qDebug() << *i;
次の表は、STLスタイルのイテレータのAPIをまとめたものである:
| 式 | 振る舞い |
|---|---|
*i | 現在の項目を返す |
++i | イテレータを次の項目に進める |
i += n | イテレータをn アイテム分進めます。 |
--i | イテレータを1アイテム分戻す |
i -= n | イテレータをn アイテム分戻す |
i - j | イテレータi とj |
++ および-- 演算子は、前置演算子 (++i,--i) および後置演算子 (i++,i--) として使用できます。前置演算子はイテレータを変更し、変更後のイテレータへの参照を返します。後置演算子はイテレータを変更する前にイテレータのコピーを取り、そのコピーを返します。戻り値を無視する式では、前置演算子 (++i,--i) を使うことをお勧めします。
constでないイテレータ型の場合、単項演算子* の戻り値を代入演算子の左辺で使用することができます。
QMap とQHash の場合、* 演算子は項目の値コンポーネントを返します。キーを取得したい場合は、イテレータで key() を呼び出します。対称性のために、イテレータ型は値を取得するvalue()関数も提供します。たとえば、QMap のすべての項目をコンソールに表示する方法を示します:
QMap<int, int>map;//...for(autoi=map.cbegin(),end=map.cend(); i!=end;++i) qDebug() << i.key() << ':' << i.value();
暗黙の共有のおかげで、関数が値ごとにコンテナを返すのは非常に安価です。Qt API には、値ごとにQList やQStringList を返す関数が多数含まれています(例:QSplitter::sizes())。STLイテレータを使用してこれらを反復処理する場合は、常にコンテナのコピーを取り、そのコピーを反復処理する必要があります。例えば
// RIGHT const QList<int> sizes = splitter->sizes(); for (auto i = sizes.begin(), end = sizes.end(); i != end; ++i) {/*...*/} // WRONG for (auto i = splitter->sizes().begin(); i != splitter->sizes().end(); ++i) {/*...*/}
この問題は、コンテナへのconstまたはconstでない参照を返す関数では発生しません。
暗黙の共有イテレータ問題
暗黙の共有は、STLスタイルのイテレータに別の結果をもたらします。イテレータがコンテナ上でアクティブになっている間は、コンテナのコピーを避けるべきです。イテレータは内部構造を指すので、コンテナをコピーする場合は、イテレータに十分注意する必要があります。例
QList<int> a, b; a.resize(100000); // make a big list filled with 0. QList<int>::iterator i = a.begin(); // WRONG way of using the iterator i: b = a; /* Now we should be careful with iterator i since it will point to shared data If we do *i = 4 then we would change the shared instance (both vectors) The behavior differs from STL containers. Avoid doing such things in Qt. */ a[0] = 5; /* Container a is now detached from the shared data, and even though i was an iterator from the container a, it now works as an iterator in b. Here the situation is that (*i) == 0. */ b.clear(); // Now the iterator i is completely invalid. int j = *i; // Undefined behavior! /* The data from b (which i pointed to) is gone. This would be well-defined with STL containers (and (*i) == 5), but with QList this is likely to crash. */
上記の例では、QList の問題のみを示していますが、この問題は、暗黙的に共有される Qt コンテナすべてに存在します。
Javaスタイルのイテレーター
Java スタイルのイテレーターは、Java のイテレーター・クラスをモデルにしています。新しいコードでは、STL スタイルのイテレータを使用する必要があります。
Qt コンテナと標準コンテナの比較
| Qt コンテナ | 最も近い標準コンテナ |
|---|---|
| QList<T> | std::vector<T> に似ている。 QList とQVector は Qt 6 で統一されました。どちらもQVector のデータモデルを使用しています。QVector はQList のエイリアスになっています。 つまり、QList はリンクリストとして実装されていないので、定数時間の挿入、削除、追加、プリペンドが必要な場合は、 |
| QVarLengthArray<T, Prealloc> | std::array<T>とstd::vector<T>のミックスに似ています。 パフォーマンス上の理由から、QVarLengthArray はサイズを変更しない限りスタックに置かれます。サイズを変更すると、自動的にヒープを使用するようになります。 |
| QStack<T> | std::stack<T>と同様、QList を継承しています。 |
| QQueue<T> | std::queue<T> と同様、QList から継承。 |
| QSet<T> | std::unordered_set<T> に似ています。内部的には、QSet はQHash で実装されている。 |
| QMap<Key, T> | std::map<Key, T> に似ている。 |
| QMultiMap<Key, T> | std::multimap<Key, T> に似ている。 |
| QHash<Key, T> | std::unordered_map<Key, T> に最も似ています。 |
| QMultiHash<Key, T> | std::unordered_multimap<Key, T> に最も近い。 |
Qt コンテナと標準アルゴリズム
Qt コンテナは#include <algorithm> の関数と一緒に使うことができます。
QList<int> list = {2, 3, 1}; std::sort(list.begin(), list.end()); /* Sort the list, now contains { 1, 2, 3 } */ std::reverse(list.begin(), list.end()); /* Reverse the list, now contains { 3, 2, 1 } */ int even_elements = std::count_if(list.begin(), list.end(), [](int element) { return (element % 2 == 0); }); /* Count how many elements that are even numbers, 1 */
その他のコンテナに似たクラス
Qt には、いくつかの点でコンテナに似たテンプレート・クラスがあります。これらのクラスはイテレータを提供せず、foreach キーワードと共に使用することはできません。
- QCache<Key, T> は、Key 型のキーに関連付けられた特定の型 T のオブジェクトを格納するキャッシュを提供します。
- QContiguousCache<T>は、通常連続的にアクセスされるデータをキャッシュする効率的な方法を提供します。
Qt のテンプレート・コンテナと競合するその他の非テンプレート型には、QBitArray 、QByteArray 、QString 、QStringList があります。
アルゴリズムの複雑さ
アルゴリズムの複雑さは、コンテナ内のアイテムの数が増えるにつれて、各関数がどの程度速く(あるいは遅く)なるかに関係する。例えば、std::リストの途中に項目を挿入するのは、リストに格納されている項目の数に関係なく、非常に高速な操作である。一方、QList の中間に項目を挿入することは、QList に多くの項目が含まれている場合、非常に時間がかかる可能性がある。なぜなら、項目の半分をメモリ上の1つの位置に移動しなければならないからである。
アルゴリズムの複雑さを表現するために、「ビッグ・オー」表記法に基づく以下の用語を使用する:
- 一定時間:O(1).ある関数が定数時間で実行されるとは、コンテナ内にいくつのアイテムが存在しても、同じ時間を必要とする場合である。一例として、QList::push_back ()がある。
- 対数時間:O(logn)。対数時間で実行される関数とは、実行時間がコンテナ内のアイテム数の対数に比例する関数である。一例として、バイナリ探索アルゴリズムがある。
- 線形時間:O(n)。線形時間で実行される関数は、コンテナに格納されているアイテムの数に正比例する時間で実行される。一例としてQList::insert() がある。
- 線形対数時間:O(nlogn)。線形対数時間で実行される関数は、線形時間関数よりは漸近的に遅いが、2次時間関数よりは速い。
- 二次時間:O(n²).2次時間関数は、コンテナに格納されたアイテム数の2乗に比例する時間で実行される。
以下の表は、逐次コンテナQList<T>のアルゴリズム複雑度をまとめたものである:
| インデックス検索 | 挿入 | 前置 | 追加 | |
|---|---|---|---|---|
| QList<T> | O(1) | O(n) | O(n) | 償却O(1) |
表中、"Amort. "は "amortized behavior "を表す。例えば、"Amort.O(1)」は、その関数を1回だけ呼び出すとO(n)の動作になるかもしれないが、複数回(例えばn回)呼び出すと平均動作はO(1)になるという意味である。
次の表は、Qtの連想コンテナと集合のアルゴリズムの複雑さをまとめたものです:
| キー検索 | 挿入 | |||
|---|---|---|---|---|
| 平均 | 最悪の場合 | 平均 | 最悪の場合 | |
| QMap<キー, T | O(logn) | O(logn) | O(logn) | O(logn) |
| QMultiMap<キー、T | O(logn) | O(logn) | O(logn) | O(logn) |
| QHash<キー, T | 償却。O(1) | O(n) | Amort.O(1) | O(n) |
| QSet<キー | Amort.O(1) | O(n) | Amort.O(1) | O(n) |
QList 、QHash 、QSet を使用すると、項目を追加するパフォーマンスはO(logn)に償却される。アイテムを挿入する前に、予想されるアイテム数でQList::reserve()、QHash::reserve()、またはQSet::reserve() を呼び出すことで、O(1)に下げることができる。次のセクションでは、このトピックについてさらに詳しく説明する。
プリミティブ型と再配置可能型の最適化
Qt コンテナは、格納されている要素が再配置可能な場合、あるいはプリミティブな場合にも、最適化されたコードパスを使用できます。しかし、型がプリミティブかリロケータブルかは、すべてのケースで検出できるわけではありません。Q_PRIMITIVE_TYPEフラグまたはQ_RELOCATABLE_TYPEフラグ付きのQ_DECLARE_TYPEINFO マクロを使用することで、型がプリミティブまたはリロケータブルであることを宣言できます。詳細と使用例については、Q_DECLARE_TYPEINFO のドキュメントを参照してください。
Q_DECLARE_TYPEINFO を使用しない場合、Qt はプリミティブ型を識別するためにstd::is_trivial_v<T> を使用し、再配置可能な型を識別するためにstd::is_trivially_copyable_v<T>とstd::is_trivially_destructible_v<T> の両方を必要とします。これは常に安全な選択であるが、パフォーマンスは最適ではないかもしれない。
成長戦略
QList QString QByteArray <QHash<Key, T>は、ハッシュ・テーブルを保持し、そのサイズはハッシュ内の項目数に比例する。コンテナの最後にアイテムが追加されるたびにデータを再割り当てするのを避けるため、これらのクラスは通常、必要以上のメモリを割り当てます。
別のQString からQString を構築する次のコードを考えてみよう:
QString onlyLetters(const QString &in) { QString out; for (qsizetype j = 0; j < in.size(); ++j) { if (in.at(j).isLetter()) out += in.at(j); } return out; }
一度に1文字を追加することで、文字列out を動的に構築する。QString の文字列に15000文字を追加すると仮定しよう。すると、QString の空きがなくなったときに、(15000回のうち)以下の11回の再割り当てが発生する:8、24、56、120、248、504、1016、2040、4088、8184、16376。最後に、QString には 16376 個の Unicode 文字が割り当てられており、そのうち 15000 個が占有されています。
上記の値は少し奇妙に見えるかもしれないが、指針がある。それは、毎回サイズを2倍にして進むということです。より正確には、次の2のべき乗から16バイトを引いた値に進みます。16バイトは8文字に相当する。QString は内部的にUTF-16を使用しているからである。
QByteArray はQString と同じアルゴリズムを使うが、16バイトは16文字に対応する。
QList<T>もこのアルゴリズムを使いますが、16バイトは16/sizeof(T)要素に対応します。
QHash<Key, T>は全く異なるケースである。QHash'の内部ハッシュ・テーブルは2の累乗で成長し、成長するたびに、qHash(key) %QHash::capacity() (バケツ数)として計算される新しいバケツにアイテムが再配置される。この記述は、QSet<T>とQCache<Key, T>にも当てはまる。
ほとんどのアプリケーションでは、Qtが提供するデフォルトの成長アルゴリズムで十分です。もっとコントロールが必要な場合は、QList<T>、QHash<Key、T>、QSet<T>、QString 、QByteArray の3つの関数を使用すると、アイテムの保存に使用するメモリの量をチェックし、指定することができます:
- capacity() は、メモリが割り当てられているアイテムの数(QHash とQSet については、ハッシュ・テーブルのバケットの数)を返します。
- reserve(size)は、明示的にサイズ・アイテム用のメモリを事前に確保します。
- squeeze() は、項目の格納に不要なメモリを解放する。
コンテナに格納する項目の数がおおよそわかっている場合は、まずreserve() を呼び出し、コンテナへの入力が終わったらsqueeze() を呼び出して、事前に割り当てた余分なメモリを解放することができます。
© 2026 The Qt Company Ltd. Documentation contributions included herein are the copyrights of their respective owners. The documentation provided herein is licensed under the terms of the GNU Free Documentation License version 1.3 as published by the Free Software Foundation. Qt and respective logos are trademarks of The Qt Company Ltd. in Finland and/or other countries worldwide. All other trademarks are property of their respective owners.
